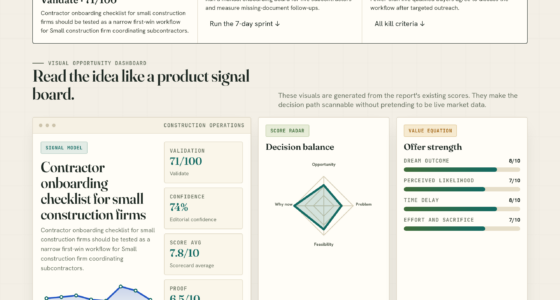
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
In 2026, the AI industry faces a turning point as data scarcity and legal restrictions make high-quality, verified data the new chokepoint. Companies are increasingly fencing valuable data, shifting the competitive landscape.
In 2026, the AI industry is confronting a new chokepoint: access to high-quality, verified data. As the era of free web scraping ends due to legal and economic barriers, companies are fencing valuable data assets, making data ownership a critical factor in AI development and competitiveness.
The industry has shifted from relying on publicly available internet data to acquiring scarce, high-value datasets stored behind paywalls, in enterprise repositories, or within specialized expert networks. This transition is driven by legal actions such as Anthropic’s $1.5 billion settlement over copyright infringement, which signals the end of free scraping. As a result, data is increasingly being licensed, bought, or protected as a strategic asset.
Meanwhile, the cost of synthetic data, once a solution to the data shortage, is rising due to risks of model collapse and errors in domains where verification is difficult. The remaining valuable data is often generated by experts—lawyers, scientists, military personnel—whose knowledge is expensive and rare. The move to expert-authored data has transformed data access into a competitive advantage, with companies investing heavily to secure exclusive datasets.
Notably, the industry is witnessing a consolidation of data providers, exemplified by the collapse of firms like Appen, which depended heavily on a few large clients. The most valuable data, however, remains inaccessible—generated through unique, hard-to-replicate activities such as combat drone annotations or proprietary research—making it impossible to rent or buy at any price.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Impact of Data Fencing on AI Industry Competition
The move to fence and license data fundamentally alters the AI landscape by creating barriers to entry for startups and smaller labs. It favors large incumbents with deep pockets capable of paying licensing fees and acquiring exclusive datasets. This trend also shifts power towards organizations with access to rare, verified data, potentially slowing innovation from smaller players and increasing industry concentration. The emphasis on data ownership as a strategic asset signals a new phase where control over information becomes as vital as compute power.
high-quality data licensing platforms
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Shifts Reshaping Data Acquisition
Historically, AI training relied on freely available internet data, with companies scraping web content at minimal cost. By 2026, legal actions such as Anthropic’s copyright settlement and ongoing lawsuits like the NYT against OpenAI have established a precedent: data used for training must be licensed or legally acquired, ending the era of unrestrained scraping. This legal environment, combined with the rising costs of synthetic data and the need for expert-verified information, has led to a market where data is increasingly seen as a paid asset.
Additionally, industry consolidation has accelerated, with companies like Meta investing billions in expert-driven data collection, while smaller firms struggle to compete. The collapse of dependency on cheap, open web data has shifted the industry toward a model where data ownership and exclusive access are central to competitive advantage.
“The Anthropic case sets a clear precedent: training data must be legally acquired, marking the end of free scraping and the rise of a licensing regime.”
— Legal expert involved in copyright settlement
expert-authored data datasets
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Impacts of Data Fencing on Innovation
It remains uncertain how smaller startups and emerging labs will adapt to the increasing costs and legal barriers around data acquisition. The long-term effects on innovation, diversity of research, and the pace of AI development are still evolving. Additionally, the precise scope of future legal restrictions and licensing costs remains unpredictable, as courts and regulators continue to shape data use policies.
synthetic data generation tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Future Developments in Data Access and Industry Structure
Expect further legal rulings that define the boundaries of data licensing and fair use, potentially increasing costs for training datasets. Companies will likely invest more in proprietary data collection, expert networks, and synthetic data refinement. Industry consolidation may intensify, with large incumbents dominating access to high-value datasets, while startups seek alternative, often more expensive, data sources. Monitoring regulatory changes and legal precedents will be crucial for industry players moving forward.
data verification services for AI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is data becoming more expensive for AI training?
Legal restrictions on web scraping, copyright enforcement, and the need for verified, high-quality datasets are driving up costs. Companies now often license data or generate it through expensive expert-driven processes.
What does the end of free data scraping mean for startups?
It raises barriers to entry, favoring large firms with resources to acquire or license exclusive datasets, potentially slowing innovation among smaller players.
Can synthetic data replace real, verified data?
While synthetic data can supplement training, it carries risks of errors and model collapse, especially in domains requiring precise verification. Real, verified data remains critical for high-stakes applications.
How might legal rulings influence future AI development?
Legal decisions will shape data licensing regimes, potentially increasing costs and restricting access, which could impact the pace and diversity of AI research and deployment.
Source: ThorstenMeyerAI.com