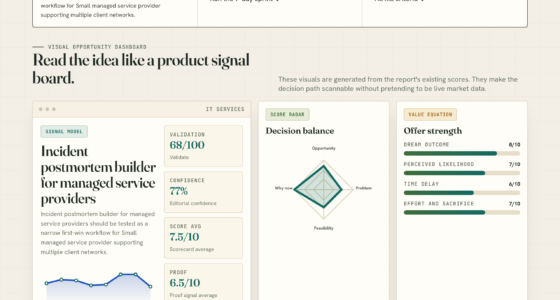
📊 Full opportunity report: Mac vs GPU Tower for Local LLMs: The Heat-and-Noise Tradeoff on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
This article compares Mac Studio and GPU towers for running local large language models, highlighting differences in heat, noise, capacity, and performance. The choice depends on model size and workload needs.
Mac Studio with Apple Silicon can run large language models (LLMs) up to 70 billion parameters on-device, offering near-silent operation with significantly lower heat and power consumption than traditional GPU towers.
This comparison hinges on two fundamental architectural differences: GPU towers prioritize memory bandwidth, enabling faster inference for models that fit within their VRAM, typically 24–32GB per GPU, but at the cost of high power draw and heat production. A single RTX 5090 GPU consumes around 575W, with multi-GPU setups exceeding 800W, creating substantial thermal management challenges.
In contrast, Apple Silicon chips like the M3 Ultra utilize a unified memory architecture, allowing up to 512GB of shared memory. This design enables the Mac to load and run larger models—such as 70B parameter models—that cannot fit into a GPU’s VRAM, albeit at slower speeds. The tradeoff is a near-silent, energy-efficient operation ideal for continuous, on-desk use.
While GPU towers excel in maximum throughput and support native CUDA ecosystems for advanced model fine-tuning, upgradeability, and multi-GPU scaling, they require ongoing thermal management and noise control efforts. Conversely, Macs require no such adjustments, offering a plug-and-play experience with minimal heat and noise, but with a performance ceiling tied to model size and inference speed.
Mac vs GPU tower
for local LLMs.
What if you sidestep the heat entirely with a different kind of machine? A tower is a high-bandwidth furnace you spend five levers quieting. Apple Silicon is near-silent by design — but asks for different tradeoffs. Match your priority in Part 2.
Put the loud, hot machine where its noise doesn’t matter, and the quiet one where you do. SSH into the tower when you need raw power; let the Mac handle everything else, silently.
Implications for AI Hardware Selection
This comparison highlights a fundamental choice for AI practitioners and enthusiasts: prioritize raw speed and upgradeability with GPU towers or opt for quiet, power-efficient operation with a Mac. For models fitting within 32GB VRAM, GPU towers remain superior in throughput. However, for larger models exceeding VRAM capacity, Apple Silicon provides a viable, low-noise alternative, potentially transforming how individuals and small teams deploy local AI systems.

Apple Mac Studio, M3 Ultra 28-Core CPU / 60-Core GPU, 256GB Unified Memory, 4TB SSD
UNMATCHED PERFORMANCE - Experience blazing-fast speeds with the M3 Ultra or M4 Max chip, featuring up to a...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Evolution of Local AI Hardware Choices
Historically, GPU towers have dominated local AI inference due to their high bandwidth and ecosystem support, especially for training and fine-tuning. Recent advances in Apple Silicon have challenged this dominance by offering large unified memory pools capable of handling bigger models at the cost of some speed. This shift reflects a broader trend towards energy-efficient, silent computing for AI workloads, especially for users prioritizing convenience and power savings over maximum throughput.
"The core tradeoff is between bandwidth and capacity. GPU towers deliver speed but at high heat and noise, while Macs offer capacity and silence at a slower pace."
— Thorsten Meyer, AI hardware expert

Ace Computers Logicad Neuron Z AI Workstation | AMD EPYC 9535 (Up to 4.3 GHz) | RTX PRO 6000 | 256GB DDR5 | 2x2TB NVMe | Windows 11 Pro | Workstation for AI, ML, DL, 3D
[ENTERPRISE-CLASS EPYC CPU FOR HPC & AI] Powered by the AMD EPYC 9535 processor with 64 cores and...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Performance and Ecosystem Gaps
It remains unclear how well future Apple Silicon models will scale for even larger models or more intensive fine-tuning tasks, given current limitations in ecosystem support and raw throughput. Additionally, the exact performance gap in real-world inference speed for models exceeding 70B parameters is still being evaluated, as benchmarks are limited.

ASUS ROG Astral LC GeForce RTX 5090 32GB GDDR7 OC Edition, NVIDIA, Graphics Card, for Desktop PC, HDMI 2.1b/DisplayPort 2.1b – 360mm AIO Cooler for Optimal Performance
Powered by the NVIDIA Blackwell architecture and DLSS 4. OC Mode: 2610 MHz/ Default Mode: 2580 MHz (Boost...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Anticipated Developments in AI Hardware
Upcoming hardware releases from NVIDIA and Apple are expected to further clarify these tradeoffs. NVIDIA may introduce more power-efficient GPUs with higher VRAM capacities, while Apple could expand unified memory and optimize inference performance. Users should monitor these developments to inform their hardware choices for local AI deployment.

Local AI on Linux in Practice : Build Private LLM Servers, GPU Workstations, Ollama Apps, Dockerized AI Services, and Self-Hosted AI Infrastructure with CUDA, ROCm, vLLM, and Open WebUI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can a Mac run any models faster than a GPU tower?
Generally no, especially for models that fit within GPU VRAM; GPU towers still outperform in raw inference speed for smaller models.
Is the heat and noise from GPU towers manageable?
Yes, but it requires ongoing thermal management, cooling solutions, and noise control efforts, which can be complex and costly.
Will Apple Silicon improve in speed with future chips?
Potentially, as Apple continues to enhance unified memory and inference capabilities, but current performance remains limited compared to high-end GPU towers for certain workloads.
Which hardware is better for large-scale fine-tuning?
GPU towers with native CUDA support and multi-GPU scaling are currently better suited for training and fine-tuning large models.
Should I choose a Mac or GPU tower for my AI projects?
It depends on your workload: for models that fit in VRAM and high throughput, a GPU tower is preferable; for larger models and silent operation, a Mac offers a compelling alternative.
Source: ThorstenMeyerAI.com