📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark reveals that there is no universally best model for defense-related AI tasks. Rankings vary based on user needs, emphasizing the importance of context in model selection.
The VigilSAR Benchmark has revealed that there is no single best model for defense-relevant AI tasks, as rankings shift based on the user’s needs. This challenges the conventional focus on capability leadership and underscores the importance of context in model deployment decisions.
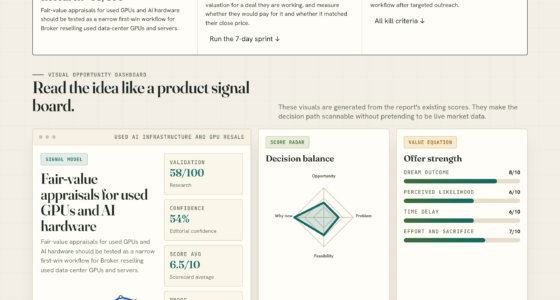
The VigilSAR Benchmark evaluates models across five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. Unlike traditional leaderboards, it scores models on their suitability for specific user profiles, such as cloud-centric or on-premises deployment. Its core finding is that a model ranked top for one profile may not be suitable for another, emphasizing that there is no universally superior model.
This benchmark is designed to measure defense-relevant competence, excluding offensive capabilities like weaponization or exploit generation. It aims to assess trustworthiness and deployability, not just raw intelligence, making it a more practical tool for decision-makers. The methodology is still evolving, and the results are early but highlight a significant shift in how AI model performance should be evaluated for sensitive applications.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Why Context-Dependent Model Selection Matters
This development matters because it shifts the focus from chasing the highest capability scores to considering deployment context, safety, and compliance. For defense and regulated sectors, a model’s trustworthiness and operational fit are more critical than raw intelligence. Recognizing that no single model fits all scenarios encourages more nuanced, responsible AI adoption, reducing risks associated with deploying models that are incompatible or unsafe in specific environments.
defense AI model deployment tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations of Traditional Capability Leaderboards
Most existing AI benchmarks prioritize raw performance and capability, often measured on general tasks and cloud-based environments. These leaderboards have driven a perception that the top-ranked model is the best choice overall. However, this approach overlooks deployment constraints, safety, and regulatory compliance, which are crucial in defense and regulated sectors. The VigilSAR Benchmark aims to fill this gap by providing a more comprehensive, context-aware evaluation framework.
Early results indicate significant variability in model rankings depending on user profiles, such as cloud-centric versus on-premises deployment, and compliance-focused versus capability-focused use cases. This underscores the limitations of traditional leaderboards in informing real-world deployment decisions.
“There is no single ‘best’ model; suitability depends entirely on the deployment context and user needs.”
— Thorsten Meyer, lead researcher at VigilSAR

AI Prompt Engineering: Foundations of Communication with LLMs – Building Generative AI and Agentic AI Prompt Systems Across Development, Testing, and Deployment (AI Engineering)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainties in Benchmark Methodology and Results
Since the VigilSAR Benchmark is still in early development, its methodology may evolve, and the current rankings are preliminary. It is not yet clear how different models will perform as the benchmark matures or how results will change with expanded evaluation axes or additional user profiles. The impact of future updates on the core finding—that no single model is best—is still uncertain.

AI for the Front Line: Primary Care Artificial Intelligence Tools for Early Detection, Risk Stratification, and Preventive Care in Family and Internal Medicine Practices
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for VigilSAR Benchmark Development
The VigilSAR team plans to refine its methodology, incorporate more models, and expand the range of user profiles tested. They aim to produce a more comprehensive and stable ranking system that better informs deployment decisions in defense and regulated sectors. Additionally, they will continue engaging with stakeholders to ensure the benchmark addresses real-world needs and concerns.

Local LLM Inference Optimization: A Comprehensive Guide to Quantization, Hardware Acceleration, and Efficient Private AI Deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why does the VigilSAR Benchmark reject the idea of a single best model?
Because model suitability depends on deployment context, safety, compliance, and operational needs. No single model excels across all these axes for every user, making context-driven evaluation essential.
How is VigilSAR Benchmark different from traditional AI leaderboards?
It evaluates models across multiple axes relevant to defense and regulated sectors, such as reliability, safety, and deployability, and re-ranks models based on different user profiles, emphasizing context-specific performance.
Is the VigilSAR Benchmark final and authoritative?
No, it is still in early development, and its methodology may evolve. Its current results are preliminary but highlight important considerations for responsible AI deployment.
What implications does this have for AI developers and users?
It encourages a shift toward more nuanced, context-aware evaluation and responsible deployment, especially in sensitive sectors like defense, where safety and compliance are paramount.
Source: ThorstenMeyerAI.com